Reproducible Builds: The Missing Foundation for Embedded CI/CD
Embedded CI/CD is often discussed in terms of automation, testing, and deployment speed. But in practice, most embedded pipelines fail long before those concerns matter. The real problem is simpler and more fundamental: the build is not reproducible.
If you cannot reliably recreate the same binary from the same source code, everything built on top of that assumption becomes unstable. Testing loses meaning. Certification becomes fragile. Debugging field issues turns into guesswork. CI/CD doesn’t fix this problem — it amplifies it.
Reproducibility is the foundation everything else depends on.
Why Embedded CI/CD Is Not “Just DevOps for Firmware”
Cloud-native CI/CD assumes a world where environments are disposable and identical. You can spin up a fresh build agent, install dependencies, run tests, deploy artifacts, and tear it down again without consequence.
Embedded systems don’t work like that.
Builds depend on cross-compilers, vendor SDKs, hardware-specific toolchains, linker scripts, and architecture constraints that cannot be ignored or abstracted away. Testing often requires physical devices or tightly coupled simulators. Deployment means flashing firmware into hardware that may already be in production, in the field, or subject to regulatory constraints.
There is also no meaningful concept of “instant rollback” in many embedded domains. A firmware update for a medical device or automotive ECU is a carefully controlled event, not a button click.
And unlike web software, embedded products are expected to live for a decade or more. That changes the entire meaning of “continuous delivery.”
Reproducibility Is a Hard Requirement, Not an Optimization
In embedded development, reproducibility is not a convenience. It is a requirement imposed by reality.
If a device fails in the field two years after release, engineers must be able to reconstruct the exact binary that was shipped. Without that, debugging becomes speculative. You are no longer analyzing the system that failed; you are analyzing something similar but not identical.
The same requirement appears in certification workflows. Standards such as ISO 26262, IEC 61508, and IEC 62304 assume traceability from source code to binary output. Auditors expect that a given commit can be rebuilt into the exact artifact that was validated.
Even small deviations in toolchain versions can break this assumption. A compiler update may change optimization behavior, memory layout, or timing characteristics. In embedded systems, those differences are not cosmetic — they can change system behavior under real-time constraints.
A reproducible build system is what keeps these differences under control.
Why Builds Stop Being Reproducible
Most teams do not lose reproducibility in a single moment. It degrades slowly over time through two main mechanisms: toolchain drift and environment rot.
Toolchain drift happens when compilers, linkers, or SDKs change between builds. Even patch-level updates can modify optimization strategies or code generation. The same source code produces a different binary, even though nothing in the project itself changed. These differences are often subtle, but in real-time systems they can affect interrupt timing, memory alignment, or stack usage.
Environment rot is more gradual but more dangerous. Build systems accumulate hidden dependencies: system libraries, environment variables, shell configurations, and undocumented assumptions about the host machine. Over time, the build environment becomes impossible to reconstruct exactly.
By the time a team tries to rebuild an older release — often years later — the original environment no longer exists in any meaningful form.
At that point, reproducibility is already lost.
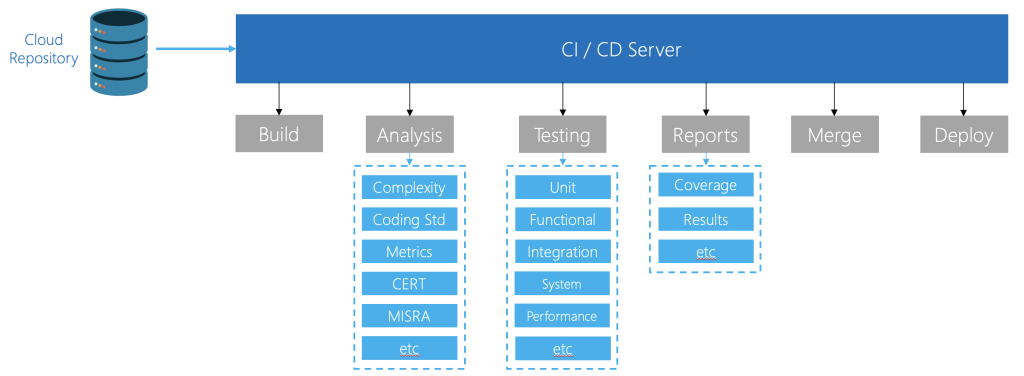
Containers as a Practical Solution
Containerization addresses both failure modes by treating the build environment itself as a versioned artifact.
A container encapsulates the compiler, toolchain, dependencies, configuration, and system environment into a single immutable image. When that image is tagged and stored alongside the source code, the entire build system becomes reproducible.
This eliminates the need to maintain fragile documentation describing how to reconstruct a build machine. Instead, the Dockerfile becomes the build specification. If the container runs, the build works.
Containers also solve a scaling problem. Embedded teams often support multiple architectures — ARM, RISC-V, and others — each requiring different toolchains. With containerization, these environments can coexist in a single CI system without conflicts or dedicated hardware.
The result is not just reproducibility, but portability of the entire build pipeline.
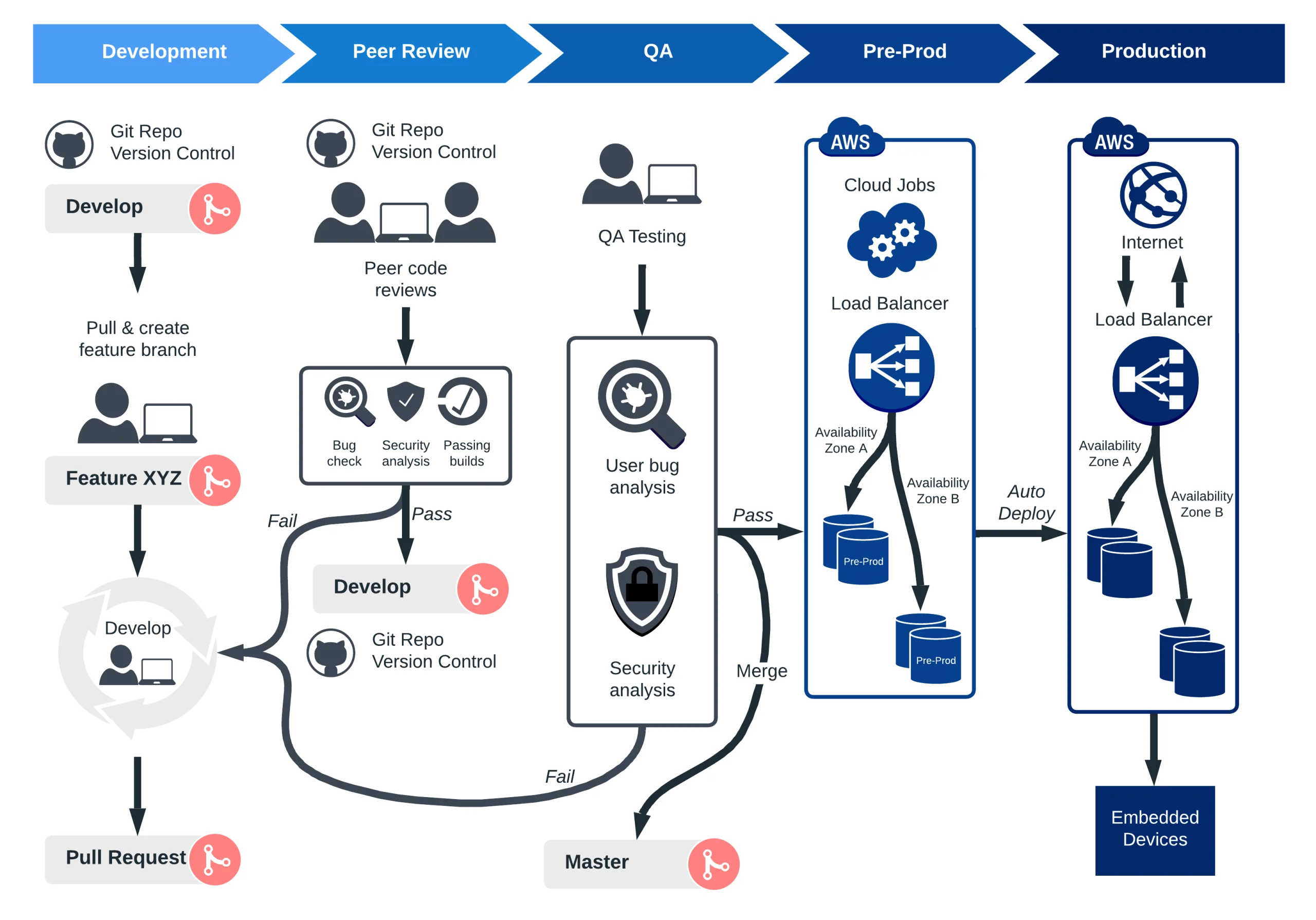
From Reproducible Builds to Embedded CI/CD
Once the build environment is stable, CI/CD becomes practical. Without that foundation, automation simply repeats inconsistencies faster.
A mature embedded CI/CD pipeline typically evolves through four stages.
It begins with containerizing the build environment. The toolchain, dependencies, and configuration are locked into a versioned image. This step establishes consistency across all machines and developers.
Next comes automated build and verification. Every commit triggers a build inside the container, along with static analysis and early validation. Issues are caught immediately rather than at release time.
The third stage introduces hardware-in-the-loop testing. Some behavior cannot be validated in simulation alone. Physical devices are integrated into the pipeline so that firmware can be flashed, executed, and verified automatically. The key advantage here is consistency: the binary tested in CI is identical to the binary that will run in production.
Finally, compliance is integrated directly into the pipeline. Instead of producing documentation at the end of development, teams generate continuous audit trails. This is especially important in regulated industries, where traceability is as important as functionality.
Common Mistakes in Embedded CI/CD Adoption
The most common mistake is trying to build everything internally. Teams attempt to design their own container infrastructure, write custom build orchestration scripts, and maintain a fully bespoke system. This often slows adoption and introduces unnecessary complexity.
A more practical approach is to start with pre-built, validated toolchain containers. These provide a known-good foundation and allow teams to focus on their actual product rather than infrastructure design.
The second major issue is licensing. Traditional node-locked licensing models do not scale in containerized CI systems, where build agents are ephemeral and distributed. Without a flexible licensing model, CI/CD pipelines quickly hit artificial limits that have nothing to do with technical capability.
The Real Goal: Confidence, Not Speed
Embedded CI/CD is often framed as a productivity improvement. In reality, its primary value is confidence.
Confidence that a firmware binary can be rebuilt years later.
Confidence that a release artifact matches what was tested and certified.
Confidence that changes in toolchains or environments have not silently altered system behavior.
Automation is only the mechanism. Reproducibility is the requirement that makes automation meaningful.
Without reproducible builds, CI/CD is just fast uncertainty. With reproducible builds, it becomes a foundation for long-term system reliability.
Closing Thought
Embedded systems are no longer short-lived firmware projects. They are long-term software systems embedded into physical reality.
And in that world, reproducibility is not an optimization. It is the difference between systems you can trust and systems you merely hope will behave the same tomorrow as they do today.