Technologies _ February 22, 2024_ admin_ 0 Comments Unlocking the Power of Kubernetes: A Comprehensive Guide LEARN MORE
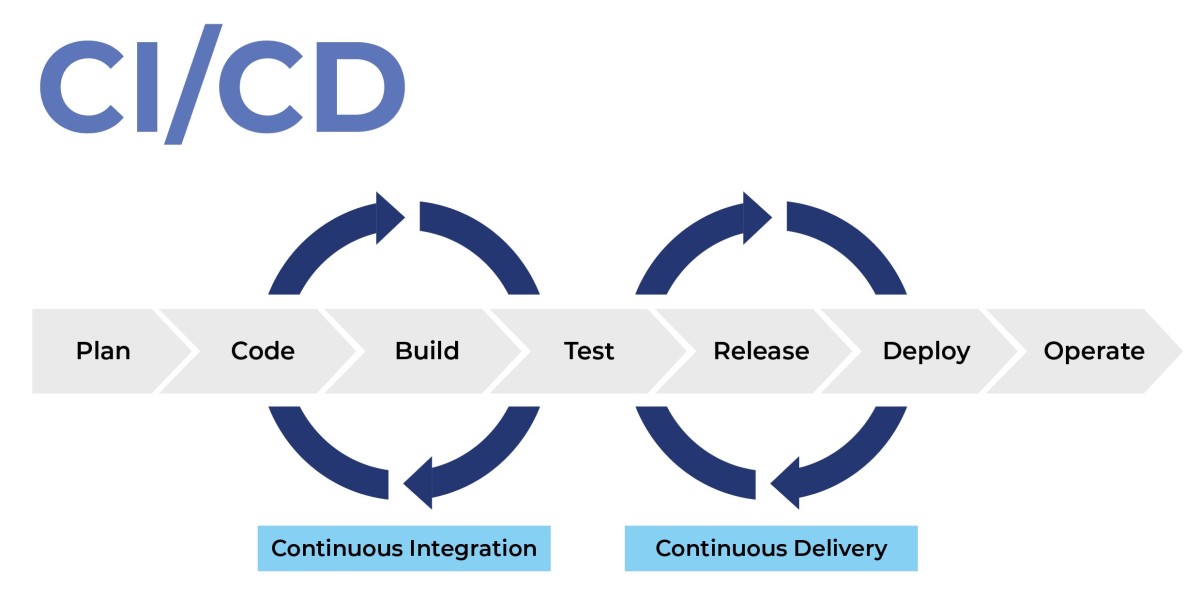
Technologies _ February 4, 2024_ admin_ 0 Comments Demystifying CI/CD: Accelerating Software Delivery with Continuous Integration and Continuous Deployment LEARN MORE
Technologies _ January 31, 2024_ admin_ 0 Comments Mastering Version Control: A Guide to Streamlining Software Development LEARN MORE
Technologies _ January 26, 2024_ admin_ 0 Comments Unleashing the Power of Container Orchestration: A Guide to Streamlining Deployment Workflows LEARN MORE
Technologies _ January 12, 2024_ admin_ 0 Comments Unveiling the Power of Virtualization: Enhancing Flexibility and Efficiency in IT Infrastructure LEARN MORE
Blog _ August 27, 2023_ admin_ 0 Comments Reverse engineering my router's firmware with binwalk LEARN MORE
Blog _ August 26, 2023_ admin_ 0 Comments Introduction to Embedded Linux Security – part 1 LEARN MORE
Blog _ August 13, 2023_ admin_ 0 Comments Introduction to Trusted Execution Environment and ARM's TrustZone LEARN MORE
Blog _ June 28, 2023_ admin_ 0 Comments What differs Android from other Linux based systems? LEARN MORE